

Our goal in this project was to detect touch on a surface located in front of a depth camera, in order to simulate a touch on a working space.
We designed and developed a robust detection algorithm which accurately models the observed surface.
Our final solution can detect individual touches which can be localized to within a few millimeters of their true position.
We chose to demonstrate our touch-detection algorithm by simulating three different keyboards which can be customized by the user: character keyboard, musical keyboard and emoticon keyboard.
The use of a virtual keyboard underlines the accuracy of the detection algorithm we produced.
We chose to work with Intel’s Depthsense 325 depth camera that gives good results with short distance detection.
All research code was developed in Matlab and then ported over to OpenCV using C++ in VS2010.

Depsense 325 depth camera
Many different cameras are already a part of our everyday life in cellphones and computers. New camera technology is being produced regularly and recently 3D depth scanning cameras have become commercially available at a price point that makes them available to a wide audience.
The Kinect from Microsoft is one such device but there are now numerous other devices on the market as well.
One such device, the Depthsense 325 has been adopted by Intel as an add-on to desktop and laptop PCs. These small cameras look much like regular webcams and as they become smaller over time they are likely to become even more widespread.
So the future looks like it will be full of depth! The question is what can we do with this new and useful sensing technology. Many people are interested in performing In-air gesturs to communicate with computers.
In this project however we focus on a more well-known means of controlling the computer: touch. The vast majority of the tech educated world is already familiar with touch interfaces.
Our goal therefore is to use the new depth sensors to help detect accurate touch events and locations on a surface which has not been prepared.
To do this we have investigated the behavior of the DS325 and determined a new algorithm which we believe is the best way to detect touches on a surface.
We can divide our project into two main parts:
The first part: The touch detection algorithm.
Implemented in c++ uses OpenCV and the DepthSense SDK.
The second part: A text editor application.
Implemented in c++ uses windows MFC and Intel’s perceptual computing SDK.
First stage: Calibration
a. Transform from 2D to 3D with Depthsense depth data
b. Selecting the working space area and finding the surface domain
c. Computing and saving the distance map from the detected surface to the surface domain
Second stage: Main run loop
a. Per frame: Transform from 2D to 3D with depthsense depth data.
b. Touch detection
c. Matching functionality according to touch area.
This stage runs before the main application loop and its purpose is to define the parameters that we will use to detect a touch during the main loop.
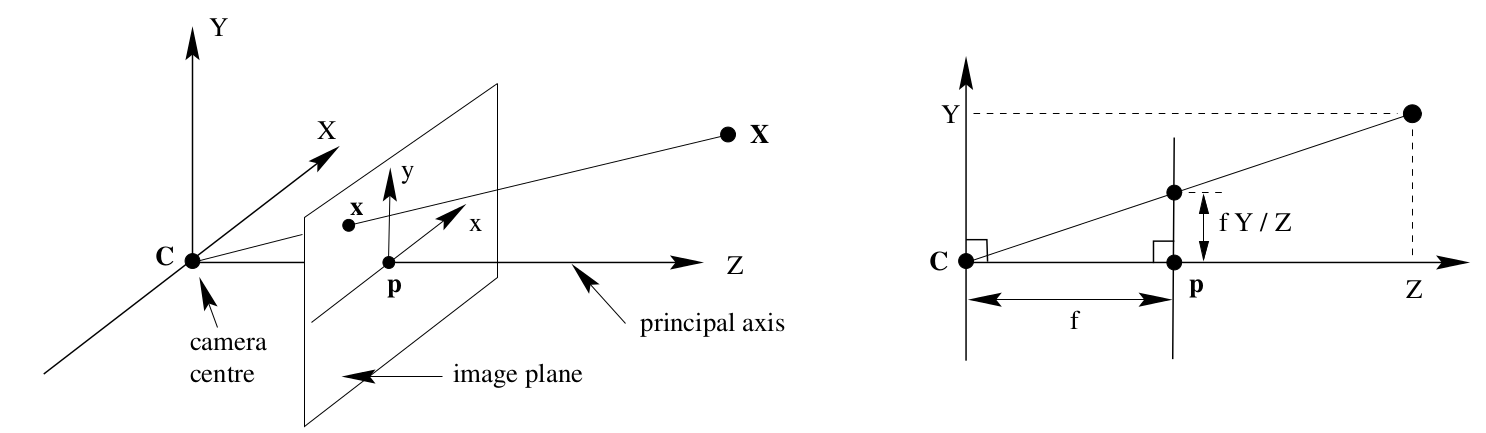
We use the Pinhole Model in order to perform projection from points in 3D to the camera plane.
We also perform the inverse operation, taking points in 2D and using the depth information to receive the corresponding 3D points.
We used the Camera Callibration Toolbox for Matlab in order to callibrate the camera and extract the intrinsic camera matrix K
and the lens distortion parameters.
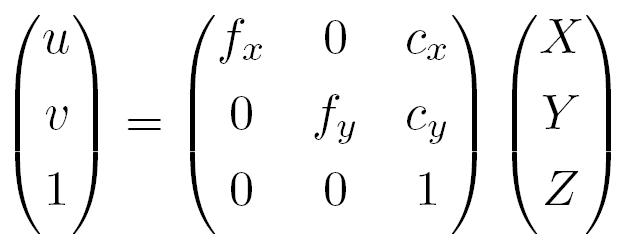
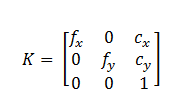
During this stage we extract a fixed number of depth images and perform processing on this data set
in order to create a denoised version of the observed surface.
This processing includes first performing a convolution with a Gaussian kernel on every frame.
This is followed by taking the average of the set of filtered frames with the end result being a significantly smoother approximation to the true surface.
There is still considerable noise in this surface especially around the edges where there are discontinuities.
We perform explicit edge detection by computing the x and y central difference approximation ( by kernel Gx and Gy) to the
derivatives of the smoothed depth image.
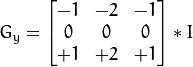
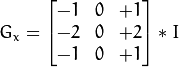
We compute the magnitude of the gradient at each point by taking the square root of the sum of the the derivatives for each pixel.
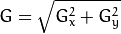
This is useful to detect discontinuities and erroneous data.
We can do this by defining a threshold on the gradient magnitude and for each pixel with a gradient that is larger than a threshold creating a pixel mask which indicates not to use that point in further computation.
We convert points from 2d screen coordinates coupled with their depth values into full 3d points in the camera's coordinate system.
This is done efficiently for every frame by pre-computing the vector inv(K)*(u;v;1) for every pixel and then during the main run loop we only need to multiply the relevant vector by its corresponding depth point to find its 3D coordinate.
After the first stage we have the 3D coordinates of the full space observed by the camera.
We now need to select the area we wish to use as our active workspace which will respond to touches. The selection is performed
by displaying the IR image to the user and subsequent selection of 4 points to specify the bounds of the surface.

Everything outside of the selected polygon is masked out and is no longer used for calculations.
We now wish to define a plane above which the selected surface area lies. We do so by finding the closest planar approximation to the points through a least
squares fit to a plane.
We achieve this by finding the SVD factorization of the surface points arranged in rows in a matrix with an additional 1 appended to the end of each row. The right eigenvector with the smallest singular value provides us with the least squares parameters for the plane.
Unless our work-surface is perfectly flat the above plane will not perfectly coincide with the height of every point on the surface.
However in order to detect whether someone is holding a finger to the surface we will need to know the accurate heights at every point on
the surface for comparison.
We do this by measuring the distance of every point in the detected surface to the surface domain e.g. in other words to the plane.
We then project each surface point onto the surface domain and project this resulting location onto the camera plane and then into screen coordinates.
This allows us to store the height of the surface from the plane at every active point in our image.
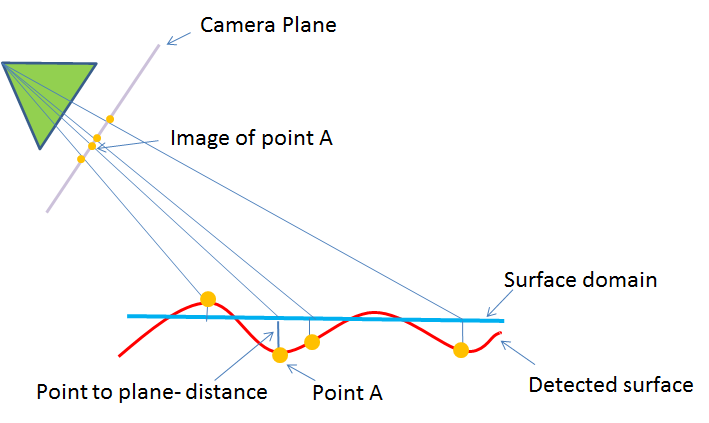
Having performed preprocessing on the data to determine the worksurface we now wish to identify touches by the user.
For each new depth frame received we perform Gaussian smoothing and remove high gradient magnitude edges as described in Section 2.1.1 .
Similarly we convert the depth image to a set of 3D points. For each 3D point we compute its height from the plane and then project onto the plane, then project onto the camera plane and into screen coordinates and then determine whether it has fallen within the surface domain.
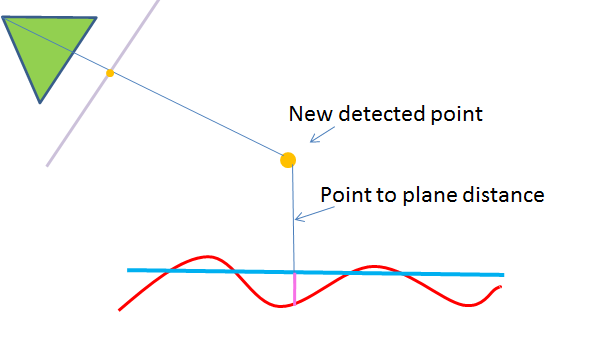
If it is within the surface domain then we subtract the height in our surface map from the height at that point from the plane.
For points which already lie on the surface this differential height value will be apprroximately zero but will fluctuate somewhat due to noise.
We therefore define a threshold height slightly above the expected noise level and everything which is higher than this threshold will be detected as a possible touch.
However clearly if a point is too high it cannot be a touch so we also define a second trhesohold to remove all points which are not touches.
The result is a binary map of deph pixels which represent likely touch points.
Of course noise still has an effect so we detect the closest grouping of 20 pixels to the camera and the average location of the pixels
in this group is considered to be a real touch location.
In order to receive a different functionality for different areas on our working surface we create a color map for every pre-defined working space.
Every area on the map coloured in a specific color and every color has its specific function related to it.
For every location of a touch detection on the surface we sample the corresponding position on the color map and perform the function that we defined for that color.

We chose to demonstrate our algorithm with a text editor application and a musical keyboard.
We created three different keyboards that need to be printed and placed in front of the camera before we run the program.
The first keyboard is a character keyboard with an option to change the text color.

The second keyboard is an Instrumental keyboard with drums and piano.
Touching different printed instruments will play different sounds.

The third keyboard is an Emoticons keyboard that allows us to print different images to the text editor.
In order to switch between the different keyboards we use the Swipe gesture from Intel’s Perceptual Computing SDK.

In this project we have demonstrated an effective algorithm for detecting touches on a surface using a depth camera.
Our method doesn’t require that the surface be flat which makes it more general than a simple straightforward plane fitting method. This also allows it to be robust to noise.
We believe that our method could be used in many different situations where it is inconvenient or too expensive to put a real touch screen. In fact it would be possible to create a touch surface by using a depth camera and a lighting projector which would give the feeling of a large touch screen television on a wall.
The detection works well but there is room for improvement. We are currently working on enabling multi touch detections. This is slightly more complicated because it requires detecting and tracking blobs in the thresholded image.
However there are many publicly available libraries which can help in this regard which we are investigating. Also, the implementation could be made considerably more efficient which is also something that we are working on. Slow response times as small as a tenth of a second can be frustrating for users. We believe we can reduce this down to the order of milliseconds.